AI
Xinity vs Ollama, vLLM, and LocalAI
Short answer: Tools like Ollama, vLLM, and LocalAI are excellent inference engines. They run a model. Xinity is the operations layer around the model that a regulated enterprise needs to run AI in production: access control, multi-model and multi-GPU orchestration, governance, and a full audit trail. Xinity uses inference engines like these under the hood. They answer "can it run the model?" Xinity answers "who can use it, under which policy, with what audit trail, across how many GPUs?"
Running a model is the easy part
If you have ever pulled a model with Ollama or spun up vLLM, you know how far open tooling has come. In minutes you have an OpenAI-compatible endpoint serving a capable open model on your own hardware. For a developer prototype, that is often all you need.
Production inside a regulated organisation is a different problem. The model is the easy part. The hard part is everything around it: who is allowed to call it, how access is controlled across teams, how every request is logged for compliance, how load is balanced across GPUs, and how the whole system is governed under EU regulation. The inference engines were not built to answer those questions, because that was never their job.
This is the distinction most comparisons miss. It is not a question of which tool is better. It is a question of which layer of the stack you are looking at.
Inference engine vs operations layer: what's the difference?
An inference engine takes a model and serves it efficiently. Ollama, vLLM, and LocalAI are inference engines. They optimise throughput, manage GPU memory, and expose an API. They do this well.
An operations layer sits above the inference engine and makes AI usable across an organisation. It handles access control, identity, observability, multi-tenancy, governance, and orchestration across multiple models and machines. Xinity is an operations layer. It runs on top of inference engines rather than replacing them.
A useful analogy: an inference engine is a database engine. An operations layer is everything that turns a database into a system a bank can run on, the access controls, the audit logs, the user management, the compliance reporting. You would not put a raw database engine into production at a regulated enterprise without that layer. The same is true for AI.
Xinity vs Ollama, vLLM, and LocalAI: feature comparison
The table below compares Xinity with three popular open-source inference engines. The point is not that the inference engines are deficient. They are excellent at what they do. The point is that running AI in regulated production requires capabilities that live above the inference layer.
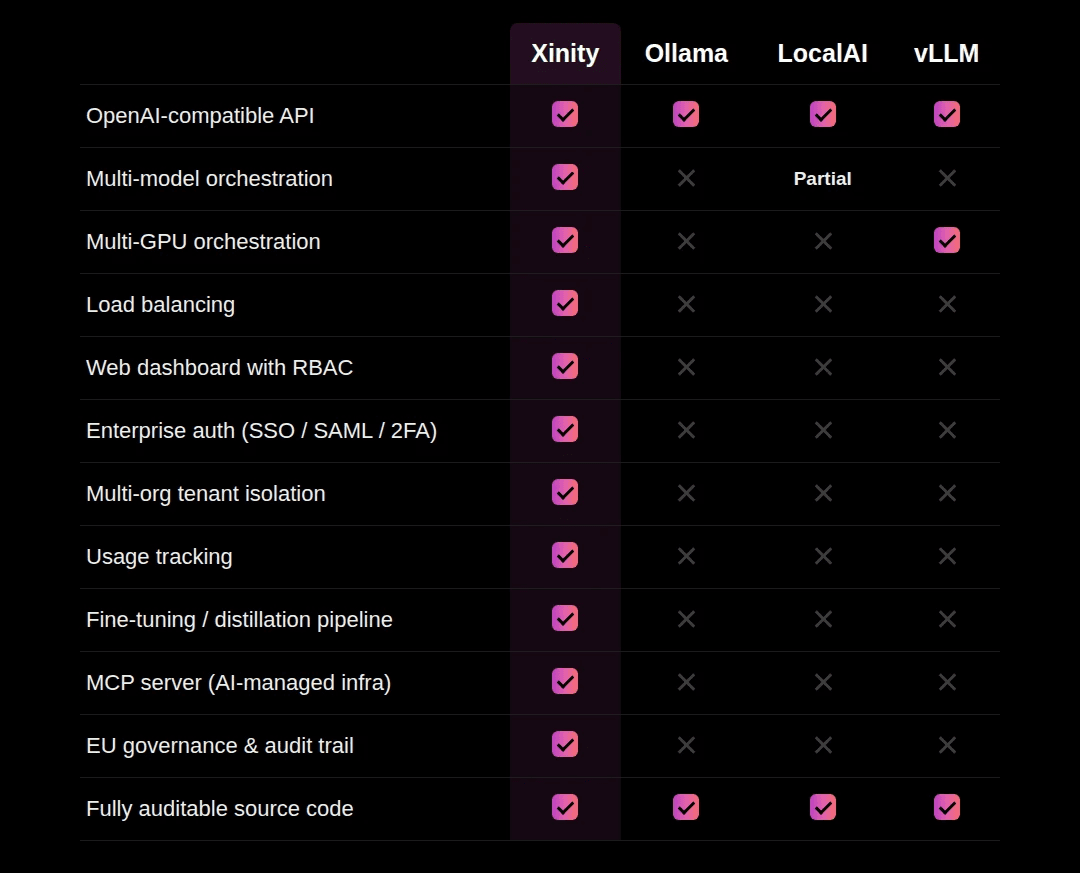
Both Ollama and vLLM are genuinely strong tools, and vLLM in particular delivers excellent multi-GPU throughput. What none of them provide out of the box is the access control, governance, and multi-tenant operations that a regulated enterprise has to have before AI can go anywhere near production data.
The questions an operations layer answers
An inference engine answers one question: can it run the model?
An operations layer answers the questions a regulated enterprise actually has to answer, often to a regulator:
Who accessed this model, and when? Identity, role-based access control, and enterprise authentication through SSO, SAML, and 2FA.
Under which policy? Multi-organisation tenant isolation so different teams and clients are cleanly separated.
With what audit trail? Usage tracking and an EU-aligned governance and audit layer that produces the evidence compliance teams need.
Across how much infrastructure? Multi-model and multi-GPU orchestration with load balancing, so the system scales without manual stitching.
These are not features you bolt on later. They are the difference between a demo and a system you can defend in an audit.
Why this matters for regulated industries
For finance, healthcare, legal, government, and defense organisations, the operations layer is not optional. These are the sectors that held back from public AI services precisely because they could not give up control of their data. For them, the value is not in accessing a model. Everyone can access a model. The value is in running AI on their own infrastructure, under their own jurisdiction, with the access control and audit trail their regulators expect.
That is what Xinity is built for: everything an enterprise needs to actually run AI in production, on its own hardware, in one open layer.
Frequently asked questions
Is Xinity a replacement for Ollama or vLLM?
No. Xinity uses inference engines like Ollama and vLLM under the hood. It adds the operations layer around them, access control, orchestration, governance, and audit, that an enterprise needs in production.
What is the difference between an inference engine and an operations layer?
An inference engine runs a model efficiently. An operations layer makes that model usable across an organisation by adding identity, access control, observability, multi-tenancy, governance, and orchestration. Xinity is an operations layer.
Does Xinity run on-premise?
Yes. Xinity is designed to run fully on an organisation's own infrastructure, so data never leaves its environment. This is what makes it suitable for regulated industries with strict data-residency and sovereignty requirements.
Is Xinity open source?
Xinity's core engine is open source and fully auditable. This matters for regulated buyers who need to verify exactly what the software does rather than trust a closed vendor.
Who is Xinity for?
Regulated European enterprises in finance, healthcare, legal, government, defense, and similar sectors, where running AI on controlled, auditable, on-premise infrastructure is a requirement rather than a preference.
Why can't I just use an inference engine in production?
You can run a model with an inference engine, but you will be missing access control, multi-tenant isolation, usage tracking, governance, and an audit trail. For a regulated enterprise, those are exactly the capabilities a regulator will ask about.