KI
Xinity im Vergleich zu Ollama, vLLM und LocalAI
Kurze Antwort: Tools wie Ollama, vLLM und LocalAI sind hervorragende Inference Engines. Sie führen ein Modell aus. Xinity ist die Betriebsebene (Operations Layer) um das Modell herum, die ein reguliertes Unternehmen benötigt, um KI in der Produktion zu betreiben: Zugriffskontrolle, Multi-Modell- und Multi-GPU-Orchestrierung, Governance und ein vollständiger Prüfpfad (Audit Trail). Xinity nutzt solche Inference Engines im Hintergrund. Sie beantworten die Frage „Kann das Modell ausgeführt werden?“. Xinity beantwortet die Frage „Wer darf es unter welcher Richtlinie, mit welchem Prüfpfad und auf wie vielen GPUs nutzen?“
Ein Modell auszuführen ist der einfache Teil
Wenn Sie jemals ein Modell mit Ollama geladen oder vLLM gestartet haben, wissen Sie, wie weit offene Tools mittlerweile sind. In wenigen Minuten haben Sie einen OpenAI-kompatiblen Endpunkt, der ein leistungsfähiges offenes Modell auf Ihrer eigenen Hardware bereitstellt. Für den Prototyp eines Entwicklers ist das oft schon alles, was man braucht.
Die Produktion in einer regulierten Organisation ist ein anderes Problem. Das Modell ist der einfache Teil. Der schwierige Teil ist das gesamte Drumherum: Wer darf es aufrufen, wie wird der Zugriff über Teams hinweg kontrolliert, wie wird jede Anfrage revisionssicher für die Compliance protokolliert, wie wird die Last auf die GPUs verteilt und wie wird das gesamte System unter EU-Regulierung verwaltet? Die Inference Engines wurden nicht gebaut, um diese Fragen zu beantworten, weil das nie ihre Aufgabe war.
Das ist der Unterschied, den die meisten Vergleiche übersehen. Es ist keine Frage, welches Tool besser ist. Es ist eine Frage, welche Ebene des Stacks man betrachtet.
Inference Engine vs. Operations Layer: Was ist der Unterschied?
Eine Inference Engine nimmt ein Modell und stellt es effizient bereit. Ollama, vLLM und LocalAI sind Inference Engines. Sie optimieren den Durchsatz, verwalten den GPU-Speicher und stellen eine API bereit. Das machen sie gut.
Eine Betriebsebene (Operations Layer) sitzt über der Inference Engine und macht KI in einer Organisation nutzbar. Sie kümmert sich um Zugriffskontrolle, Identität, Observability, Mandantenfähigkeit, Governance und die Orchestrierung über mehrere Modelle und Maschinen hinweg. Xinity ist eine solche Betriebsebene. Sie läuft auf den Inference Engines, anstatt sie zu ersetzen.
Eine nützliche Analogie: Eine Inference Engine ist wie eine Datenbank-Engine. Eine Betriebsebene ist all das, was eine Datenbank in ein System verwandelt, auf dem eine Bank laufen kann – die Zugriffskontrollen, die Audit-Logs, die Benutzerverwaltung, die Compliance-Berichte. Ohne diese Ebene würde man im regulierten Unternehmensbereich keine nackte Datenbank-Engine in Betrieb nehmen. Das Gleiche gilt für KI.
Xinity vs. Ollama, vLLM und LocalAI: Funktionsvergleich
Die folgende Tabelle vergleicht Xinity mit drei beliebten Open-Source-Inference-Engines. Es geht nicht darum, dass die Inference Engines unzureichend sind. Sie sind exzellent in dem, was sie tun. Der Punkt ist, dass der Betrieb von KI in einer regulierten Produktion Funktionen erfordert, die oberhalb der Inference-Ebene angesiedelt sind.
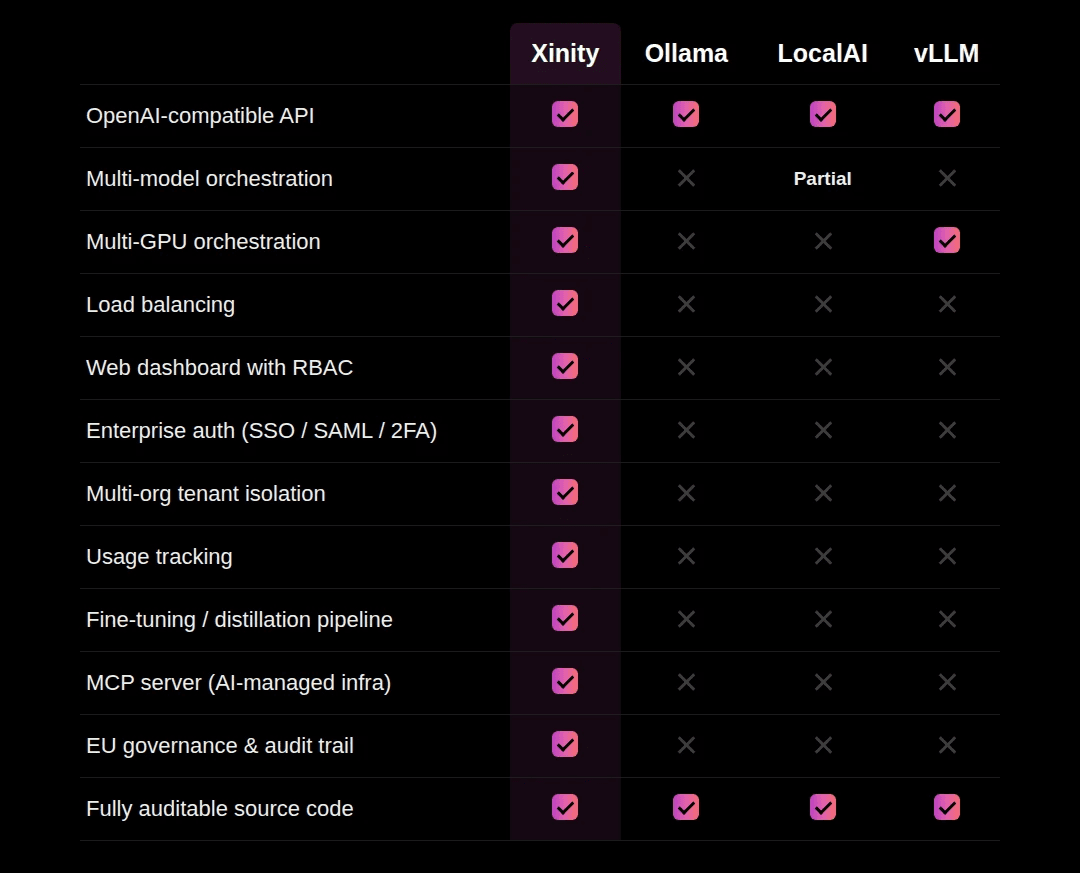
Sowohl Ollama als auch vLLM sind wirklich starke Tools, und insbesondere vLLM liefert einen hervorragenden Multi-GPU-Durchsatz. Was keines von ihnen standardmäßig bietet, sind die Zugriffskontrolle, die Governance und der mandantenfähige Betrieb, die ein reguliertes Unternehmen zwingend benötigt, bevor KI überhaupt in die Nähe von Produktionsdaten gelangen darf.
Die Fragen, die eine Betriebsebene beantwortet
Eine Inference Engine beantwortet eine Frage: Kann das Modell ausgeführt werden?
Eine Betriebsebene beantwortet die Fragen, die ein reguliertes Unternehmen tatsächlich beantworten muss – oft gegenüber einer Aufsichtsbehörde:
Wer hat wann auf dieses Modell zugegriffen? Identität, rollenbasierte Zugriffskontrolle und Enterprise-Authentifizierung über SSO, SAML und 2FA.
Unter welcher Richtlinie? Mandantentrennung für mehrere Organisationen, damit verschiedene Teams und Kunden sauber voneinander getrennt sind.
Mit welchem Prüfpfad? Nutzungsverfolgung sowie eine EU-konforme Governance- und Audit-Ebene, die die Nachweise liefert, die Compliance-Teams benötigen.
Über wie viel Infrastruktur hinweg? Multi-Modell- und Multi-GPU-Orchestrierung mit Lastverteilung, damit das System ohne manuelle Bastelei skaliert.
Das sind keine Funktionen, die man später einfach anflanscht. Sie sind der Unterschied zwischen einer Demo und einem System, das man in einem Audit verteidigen kann.
Warum das für regulierte Branchen wichtig ist
Für Finanzdienstleister, das Gesundheitswesen, den Rechtsbereich, Behörden und Verteidigungsorganisationen ist die Betriebsebene nicht optional. Dies sind die Sektoren, die sich bei öffentlichen KI-Diensten zurückgehalten haben, eben weil sie die Kontrolle über ihre Daten nicht abgeben konnten. Für sie liegt der Wert nicht im Zugriff auf ein Modell. Jedes Unternehmen kann auf ein Modell zugreifen. Der Wert liegt darin, KI auf der eigenen Infrastruktur, unter der eigenen Rechtsprechung und mit den von ihren Regulierungsbehörden erwarteten Zugriffskontrollen und Prüfpfaden zu betreiben.
Genau dafür ist Xinity gebaut: alles, was ein Unternehmen braucht, um KI tatsächlich in der Produktion zu betreiben, auf eigener Hardware, in einer offenen Ebene.
Häufig gestellte Fragen
Ist Xinity ein Ersatz für Ollama oder vLLM?
Nein. Xinity nutzt Inference Engines wie Ollama und vLLM im Hintergrund. Es fügt die Betriebsebene um sie herum hinzu – Zugriffskontrolle, Orchestrierung, Governance und Audit –, die ein Unternehmen in der Produktion benötigt.
Was ist der Unterschied zwischen einer Inference Engine und einer Betriebsebene?
Eine Inference Engine führt ein Modell effizient aus. Eine Betriebsebene macht dieses Modell in einer Organisation nutzbar, indem sie Identität, Zugriffskontrolle, Observability, Mandantenfähigkeit, Governance und Orchestrierung hinzufügt. Xinity ist eine Betriebsebene.
Läuft Xinity On-Premise?
Ja. Xinity ist so konzipiert, dass es vollständig auf der eigenen Infrastruktur eines Unternehmens läuft, sodass Daten die eigene Umgebung nie verlassen. Das macht es ideal für regulierte Branchen mit strengen Anforderungen an Datenresidenz und Datensouveränität.
Ist Xinity Open Source?
Der Kern von Xinity ist Open Source und vollständig überprüfbar (auditable). Das ist wichtig für Kunden aus regulierten Bereichen, die genau überprüfen müssen, was die Software tut, anstatt einem geschlossenen Anbieter blind zu vertrauen.
Für wen ist Xinity gedacht?
Regulierte europäische Unternehmen in den Bereichen Finanzen, Gesundheitswesen, Recht, Behörden, Verteidigung und ähnlichen Sektoren, in denen der Betrieb von KI auf kontrollierter, überprüfbarer On-Premise-Infrastruktur eine zwingende Anforderung und keine bloße Präferenz ist.
Warum kann ich nicht einfach eine Inference Engine in der Produktion verwenden?
Sie können ein Modell mit einer Inference Engine betreiben, aber es fehlen Ihnen dann Zugriffskontrolle, Mandantentrennung, Nutzungsverfolgung, Governance und ein Prüfpfad. Für ein reguliertes Unternehmen sind das genau die Funktionen, nach denen eine Aufsichtsbehörde fragen wird.